Sentence-level Quality Estimation for English-German Machine Translation
The aim of the project is to exploit Natural Language Processing techniques to find the most suitable way of evaluating machine translation quality. The focus was on English-German corpora, where we showed that the use of a hierarchy of BiLSTMs along with adaptive max-pooling layers resulted in the best performance compared to:
* The use of pre-trained sentence-level embedding
* Using GloVe word embedding along with traditional machine learning regressors
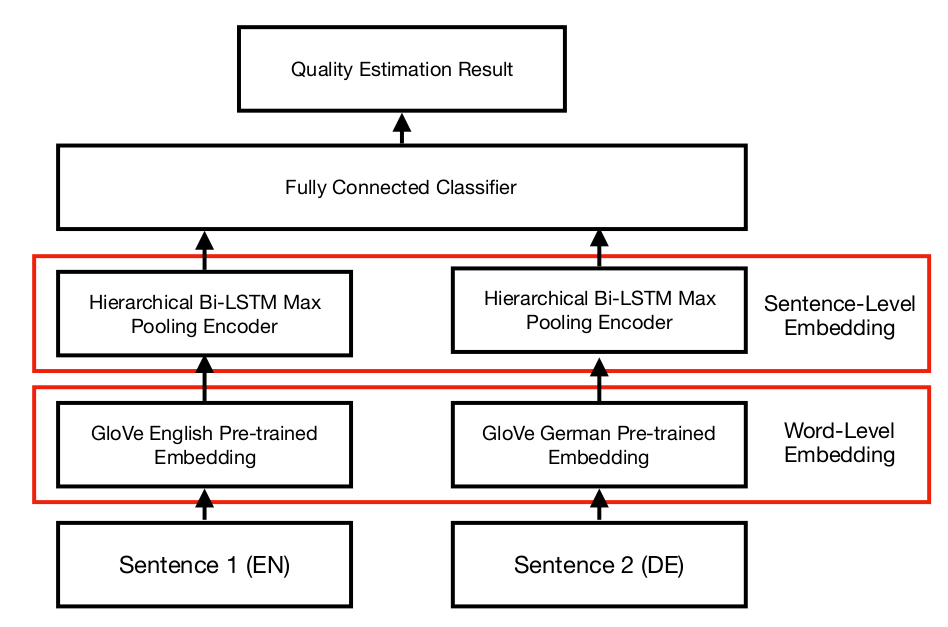
The general architecture of our model:
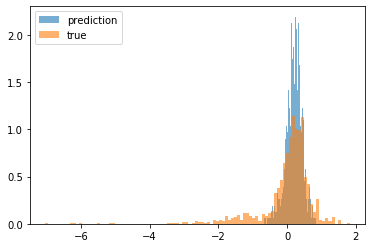
The histogram of the distributions of both trained and real scores